Duplicate content remains a common obstacle when it comes to increasing organic search traffic on retailer websites.
Here are some of the advantages of addressing duplicate content to increase SEO performance, compared to other marketing activities like link building, content marketing, or content promotion:
- Duplicate content consolidation can be executed relatively quickly, as it requires a small set of technical changes;
- You will likely see improved rankings within weeks after the correction are in place;
- New changes and improvements to your site are picked up faster by Google, as it has to crawl and index fewer pages than before.
Consolidating duplicate content is not about avoiding Google penalties. It is about building links. Links are valuable for SEO performance, but if links end up in duplicate pages they don’t help you. They go to waste.
Duplicate Content Dilutes Links
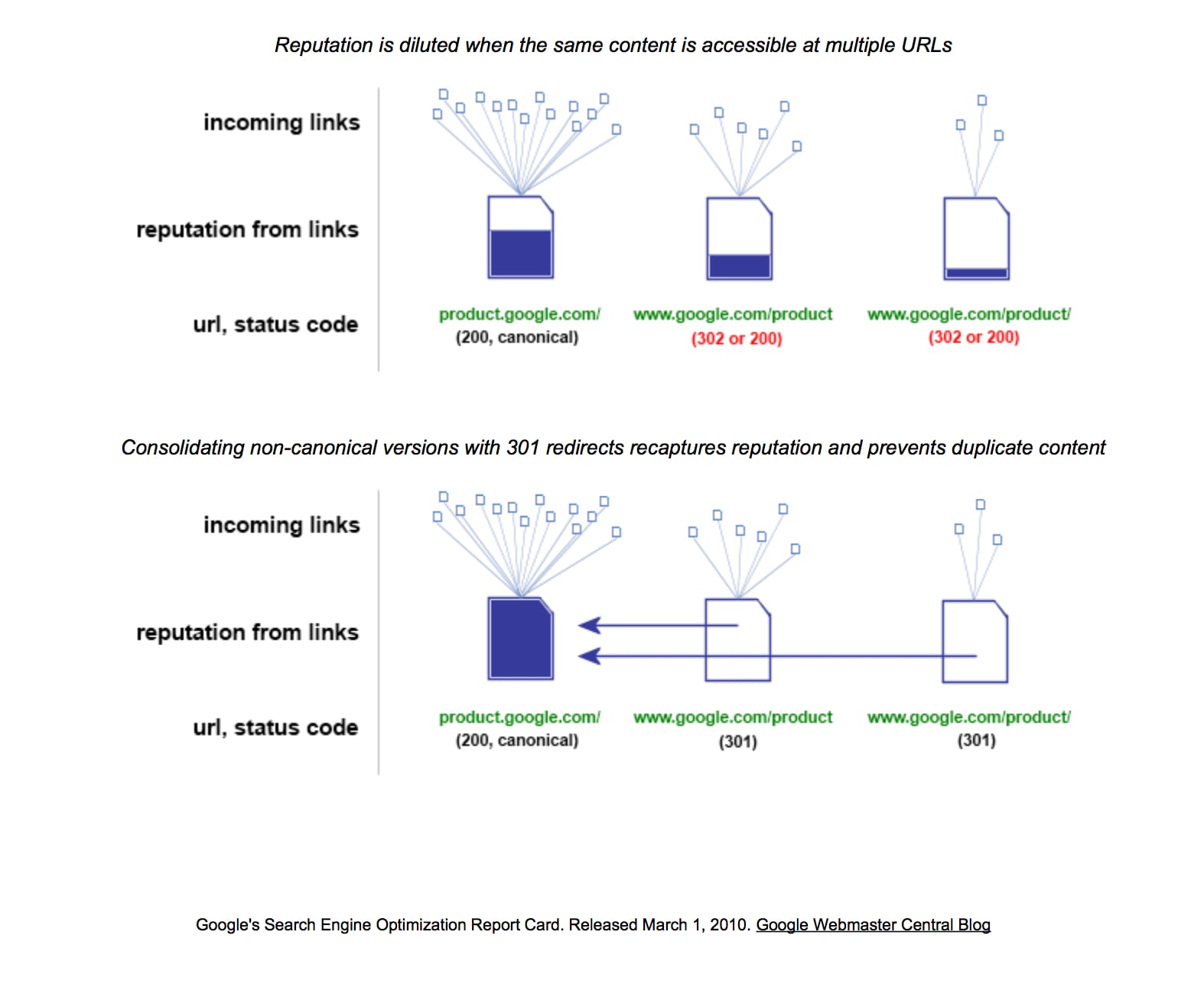
The same content being accessible by multiple URLs dilutes reputation. Source: Google.
I found the best explanation of this years ago when Google published an SEO audit (PDF) that it conducted on its own sites.
The top portion of the illustration above has three pages of the same product. Each one of them accumulates links and corresponding page reputation. Google and other major search engines still consider the quality and quantity of links from third party sites as a kind of endorsement. They use those links to prioritize how deep and often they visit site pages, how many they index, how many they rank, and how high they rank.
The reputation of the main page, also known as the canonical page, is diluted because the other two pages receive part of the reputation. Because they have the same content, they will be competing for the same keywords, but only one will appear in search results most of the time. In other words, those links to the other pages are wasted.
The lower portion of the illustration shows that by simply consolidating the duplicates, we increase the links to the canonical page, and its reputation. We reclaimed them.
The results can be dramatic. I’ve seen a 45 percent increase in revenue year over year — over $200,000 in less than two months — from removing duplicate content. The extra revenue is coming from many more product pages that previously didn’t rank and didn’t receive search-engine traffic due to duplicate content.
How to Detect Duplicate Content
To determine if your site has duplicate content, type in Google site:yoursitename.com, and check how many pages are listed.
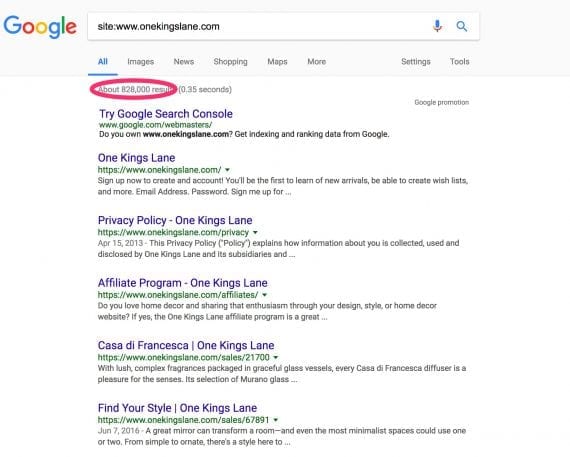
Type in Google “site:yoursitename.com”, and check how many pages are listed.
Products should make up the bulk of the pages on most retailer sites. If Google lists far more pages than you have products, your site likely has duplicate content.
If your XML sitemaps are comprehensive, you can use Google Search Console and compare the number of pages indexed in your XML sitemaps versus the number of total indexed pages in Index Status.
Duplicate Content Example
One Kings Lane is a retailer of furniture and housewares. Using a diagnostic tool, I can see that Onekingslane.com has over 800,000 pages indexed by Google. But it appears to have a duplicate content problem.
In navigating the site, I found a product page — a blue rug — that has no canonical tag to consolidate duplicate content. When I searched in Google for the product name — “Fleurs Rug, Blue” — it appeared to rank number one.
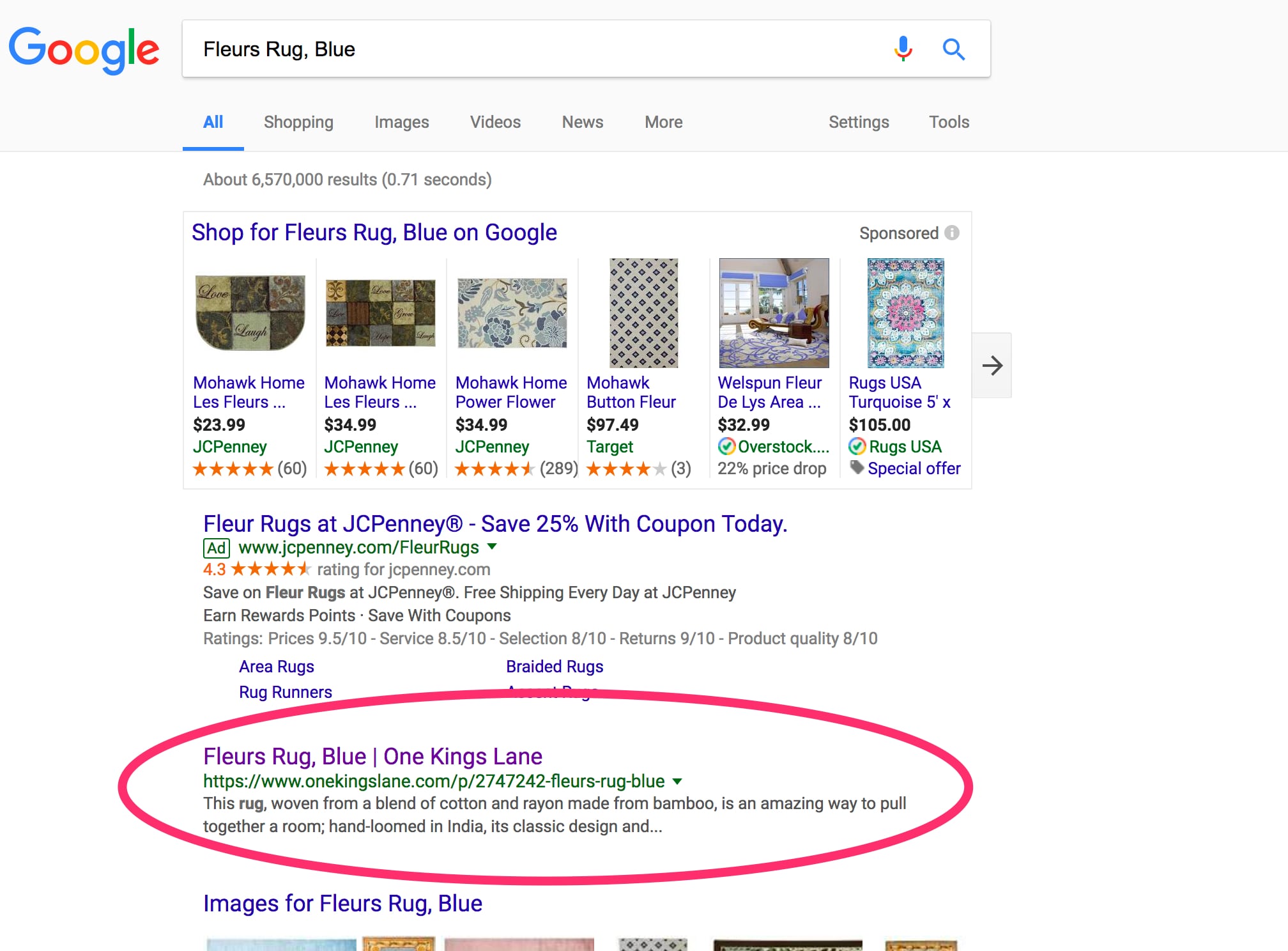
One Kings Lane has a top rank on Google for “Fleurs Rug, Blue” despite not having canonical tags.
But, when I clicked on that search listing, I went to a different page. The product IDs are different: 4577674 versus 2747242. I get one page while navigating the site, another indexed, and neither has canonical tags.
This is likely causing a reputation dilution, even though the page ranks number one for the search “Fleurs Rug, Blue.” But most product pages rank for hundreds of keywords, not just the product name. In this case, the dilution is likely causing the page to rank for far fewer terms that it otherwise could.
However, duplicate content is not the biggest issue in this example. When I clicked on that search result, I went to a nonexistent page.
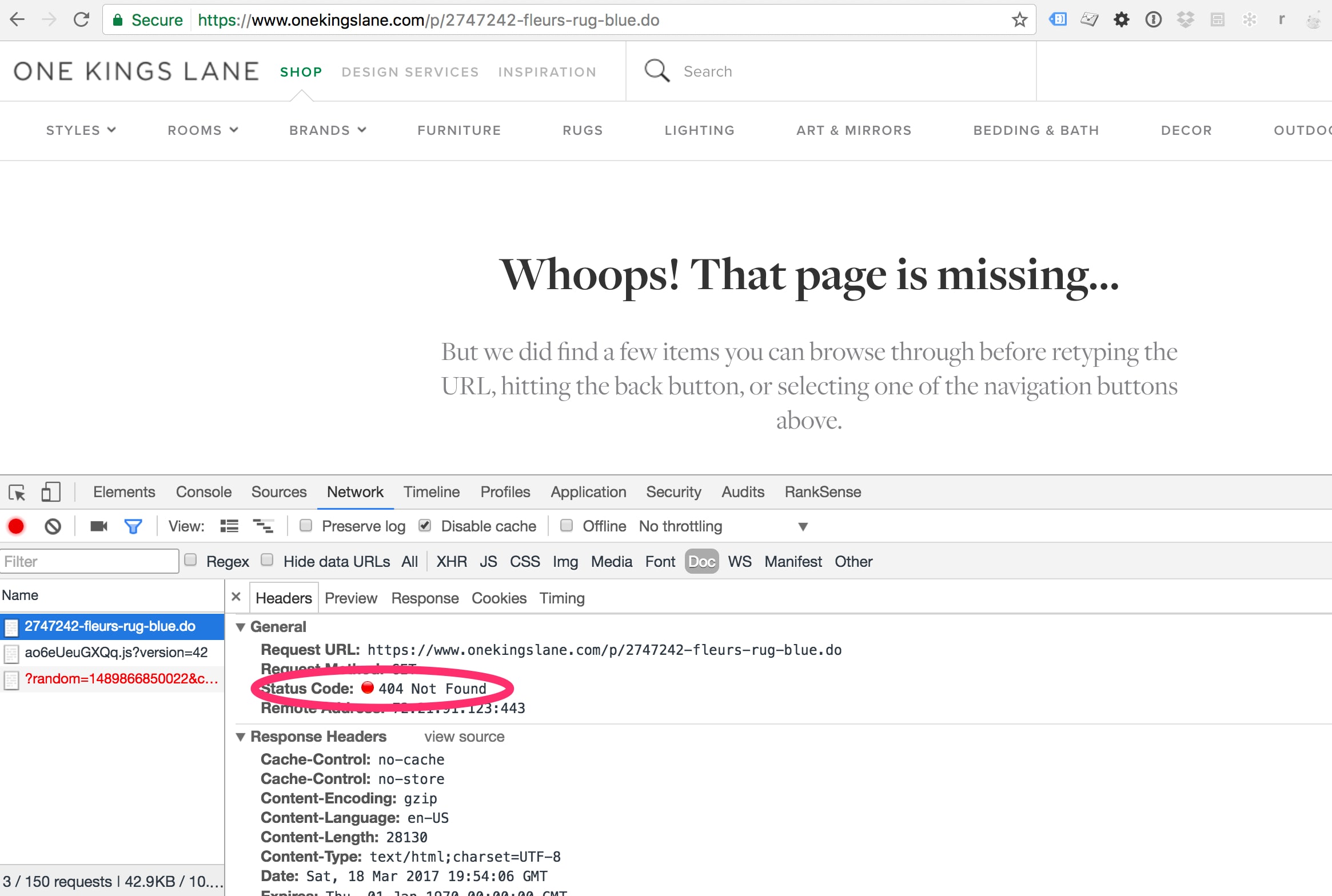
Clicking the search result for the blue rug produced an error page.
The page no longer exists. Google will likely drop this product from the search results.
Even if One Kings Lane rebuilds the product page, giving it a new product ID, it could take weeks for Google to pick it up, as Googlebot has to crawl at least 800,000 pages on the entire site.
Correcting Duplicate Content
An outdated tactic to address duplicate content is to block search engines from crawling the duplicate pages in the robots.txt file. But this does not consolidate the reputation of the duplicates into the canonical pages. It avoids penalties, but it does not reclaim links. When you block duplicate pages via robots.txt, those duplicate pages still accumulate links, and page reputation, which doesn’t help the site.
Instead, what follows are recipes to address the most common duplicate content problems using 301 redirects in Apache. But first, it’s helpful to understand the use cases for permanent redirects and canonical tags.
Canonical tags and redirects both consolidate duplicate pages. But, redirects are generally more effective because search engines rarely ignore them, and the pages redirected don’t need to be indexed. However, you can’t (or shouldn’t) use redirects to consolidate near duplicates, such as the same product in different colors, or products listed in multiple categories.
The best duplicate content consolidation is the one that you don’t have to do. For example, instead of creating a site hierarchy with site.com/category1/product1, simply use site.com/product1. It eliminates the need to consolidate products listed in multiple categories.
Common URL Redirects
What follows are Apache redirect recipes to address five common duplicate content problems.
I will use mod_rewrite, and assume it is enabled on your site
RewriteEngine On # This will enable the Rewrite capabilities
I will also use htaccess checker to validate my rewrite rules.
Protocol duplication. We want to make sure we only have our store accessible via HTTP or HTTPS, but not both. (I addressed the process of moving a web store to HTTPS, in “SEO: How to Migrate an Ecommerce Site to HTTPS.”) Here I will force HTTPS.
RewriteEngine On
# This will enable the Rewrite capabilities
RewriteCond %{HTTPS} !=on
# This checks to make sure the connection is not already HTTPS
RewriteRule ^/?(.*) https://www.webstore.com/$1 [R=301,L]
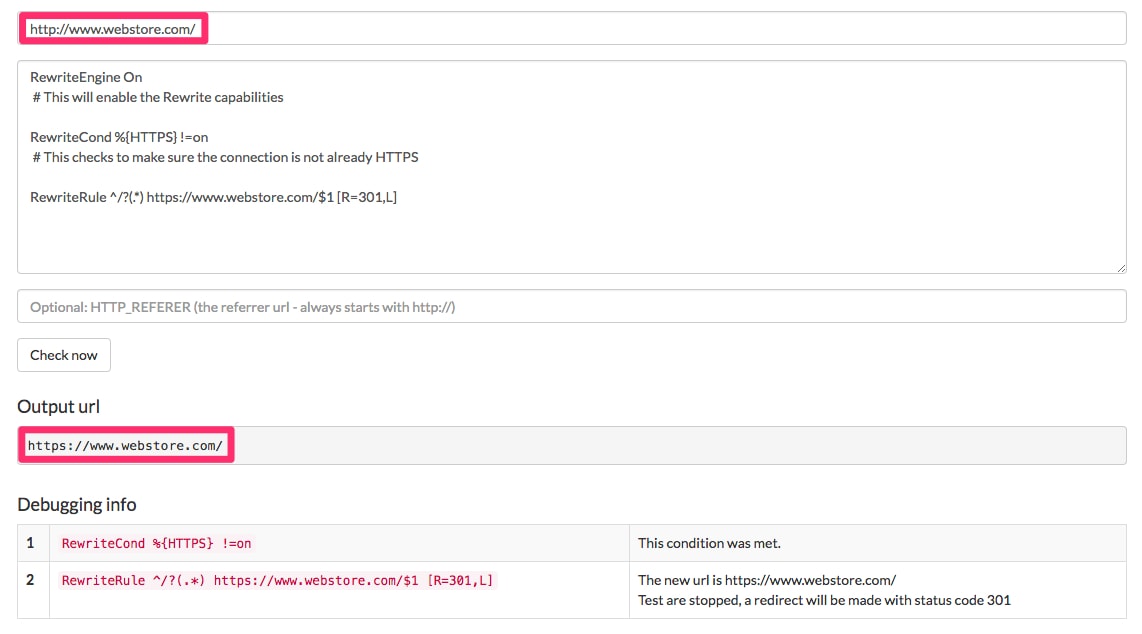
This checks to make sure the connection is not already HTTPS.
Note that this rule will also address the rare case of IP duplication, where the site is also available via the IP address.
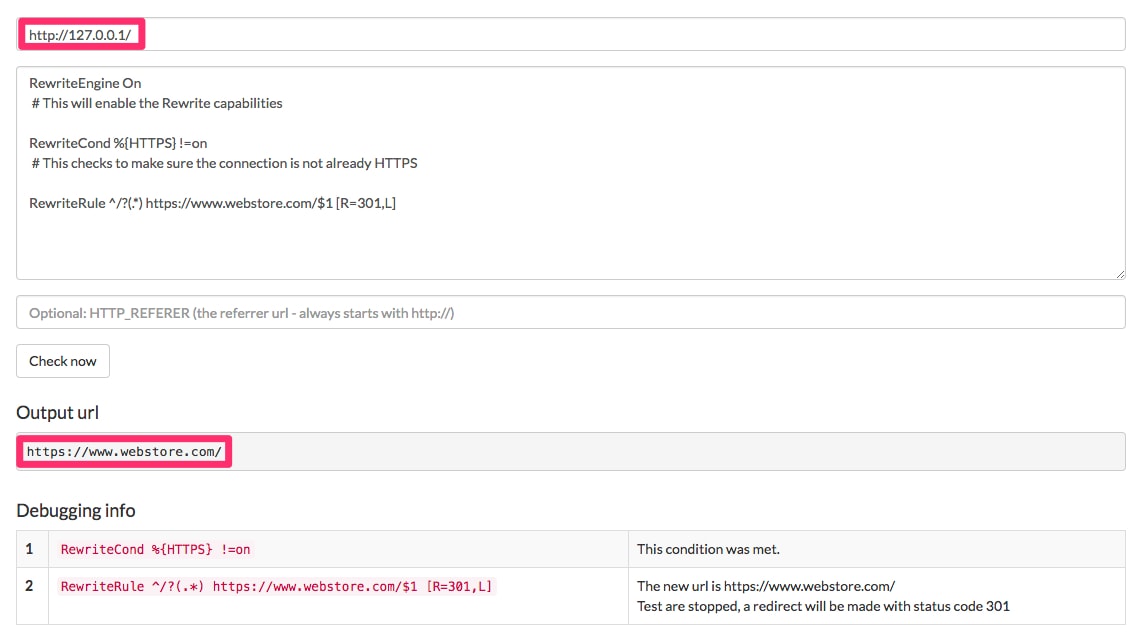
This rule will also work to address the rare case of IP duplication, where the site is also available via the IP address.
For the next examples, we are going to assume we have the full site using HTTPS.
Trailing slash duplication. We want to make sure we only have pages with a trailing slash or without a trailing slash, but not both. Below you can find examples of how to accomplish both cases.
This rule adds missing trailing slashes:
RewriteEngine On
# This will enable the Rewrite capabilities
%{REQUEST_FILENAME} !-f
# This checks to make sure we don’t add slashes to files, i.e. /index.html/ would be incorrect
RewriteRule ^([^/]+)/?$ https://www.webstore.com/$1/ [R=301,L]

This rule adds missing trailing slashes.
This one removes them:
RewriteEngine On
# This will enable the Rewrite capabilities
%{REQUEST_FILENAME} !-f
# This checks to make sure we don’t add slashes to files, i.e. /index.html/ would be incorrect
RewriteRule (.+)/$ https://www.webstore.com/$1 [R=301,L]
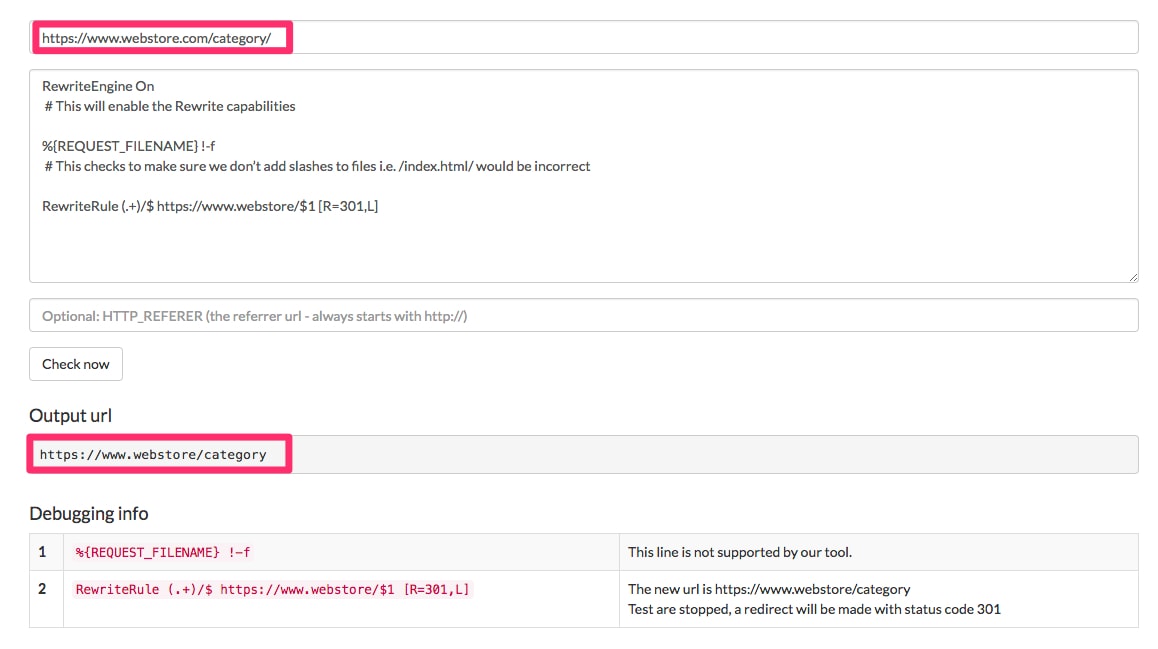
This rule removes missing trailing slashes.
File duplication. A common case of a duplicate file is the directory index file. In PHP based systems, it is index.php. In .NET systems, it is default.aspx. We want to remove this directory index file to avoid the duplicates.
%{REQUEST_FILENAME} -f
# This is optional and checks to make sure we are only affecting files
RewriteRule (.*)/?index.php$ https://www.webstore.com/$1 [R=301,L]
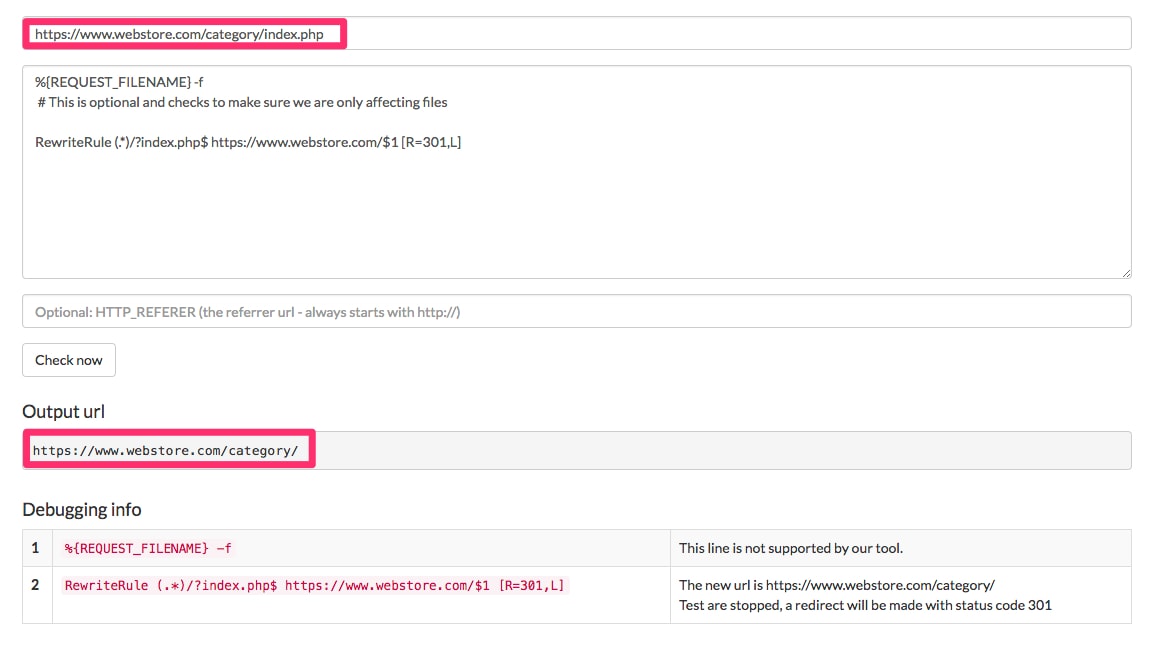
This rule removes this directory index file.
Legacy pages duplication. Another common scenario is ecommerce systems that add search-engine-friendly URLs, while leaving the equivalent non-search-engine-friendly URLs accessible without redirects.
RewriteCond %{QUERY_STRING} ^id=([0-9]+)
#this makes sure we only do it when there are ids in the URL query strings
RewriteRule ^category/product.php /product-%1.html? [R=301,L]
#Note that regular expression matches from a RewriteCond are referenced using % but those in a RewriteRule are referenced using $

This rule stops non-search engine friendly URLs from being accessible without redirects.
One-to-one Redirects
In the examples above, I am assuming that the product IDs are the same for both URLs — the canonical version and the duplicate. This makes it possible to use a single rule to map all product pages. However, the product IDs are oftentimes not the same or the new URLs don’t use IDs. In such cases, you will need one-to-one mappings.
But massive one-to-one mappings and redirects will greatly slow down a site — as much as 10 times slower in my experience.
To overcome this, I use an application called RewriteMap. The specific MapType to use in this case is the DBM type, which is a hash file, which allows for very fast access.
When a MapType of DBM is used, the MapSource is a file system path to a DBM database file containing key-value pairs to be used in the mapping. This works exactly the same way as the txt map, but is much faster, because a DBM is indexed, whereas a text file is not. This allows more rapid access to the desired key.
The process is to save a one-to-one mapping file into a text file. The format is described below Then, use the Apache tool httxt2dbm to convert the text file to a DBM file, such as the following example.
$ httxt2dbm -i productsone2one.txt -o productsone2one.map
After you create the DBM file, reference it in the rewrite rules. The previous rule can be rewritten as:
RewriteMap products “dbm:/etc/apache/productsone2one.map”
#this maps includes old URLs mapped to new URLs
RewriteCond %{QUERY_STRING} ^id=([0-9]+)
#this makes sure we only do it when there are ids in the URL query strings
RewriteRule ^(.*)$ ${products:$1|NOTFOUND} [R=301,L]
#this looks up any legacy URL in the map, and 301 redirects to the replacement URL also found in the file
#if the mapping is not in the dbm file, the server will return 404
Basically, reference the map and name it products. Then use the map in the rewrite rule. In this case, if there is no match for a legacy product URL, I’m returning a 404 error so I can find those pages in Google Search Console and add them to the map. If we returned the same page, it would create a redirect loop. There are more complicated solutions that can address this, but are outside the scope of this article.
Recommended

Remembering Hamlet Batista
February 8, 2021