
There is a long held belief that search engines – namely Google – penalize websites that duplicate content or produce material that is largely the same as other sites on the Internet. But, I’m here to tell you, The Duplicate Content Penalty is a myth.
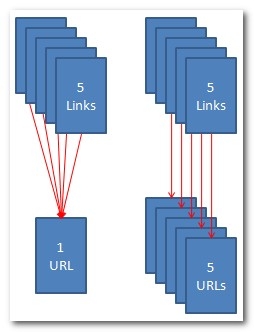 Think about it this way. If a page of content has five links into it and that page of content only loads at one URL, then all five of those links will flow their link popularity to a single URL. But imagine that same page of content with five links pointing to it that loads at five different URLs. Each of those duplicate URLs for that same piece of content now get a single link’s worth of passed link popularity. They’re each only one-fifth as strong as the single URL with all five links pointing to it.
Think about it this way. If a page of content has five links into it and that page of content only loads at one URL, then all five of those links will flow their link popularity to a single URL. But imagine that same page of content with five links pointing to it that loads at five different URLs. Each of those duplicate URLs for that same piece of content now get a single link’s worth of passed link popularity. They’re each only one-fifth as strong as the single URL with all five links pointing to it.
The Duplicate Content Penalty myth fosters misunderstanding about the real issue: link popularity. The ideal scenario for SEO is one URL for one page of content with one keyword target. I would advise ecommerce merchants to focus their efforts on optimization rather than penalty avoidance.
Causes of Content Duplication
Many different factors result in duplicate content, but one statement is true for them all: Duplicate content doesn’t exist unless there’s a link to it. If a site has duplicate content it’s because there’s at least one link to the same content at different URLs. Links to duplicate content URLs can crop up in breadcrumbs when tracking parameters are appended, when a site doesn’t link consistently by subdomain, when filtering and sorting options append parameters to the URL, when print versions generate a new URL, and many more ways. Worse, each of these can compound the other sources of duplicate content, spawning hundreds of URL variations for the same single page of content.
Home pages would be one example. In some cases, the domain resolves as the home page but clicking on the navigational links to the home page (the same page of content) results in a different URL. Banana Republic has 18 Google-indexed versions of its home page, and several others that aren’t indexed, including:
- http://www.bananarepublic.com/
- http://bananarepublic.gap.com/
- http://bananarepublic.gap.com/?ssiteID=plft
- http://bananarepublic.gap.com/?kwid=1&redirect=true
- http://bananarepublic.gap.com/browse/home.do?ssiteID=ON
Each of these home page URLs has at least one page linking to it. Think how much stronger this page could be if every one of the links pointed to each duplicate home page URL instead of being linked to http://www.bananarepublic.com/.
Types of Content Duplication
Canonical
Lack of canonicalization is a common source of duplicate content. Canonicalization refers to the removal of duplicate versions, or in SEO, to the consolidation of link popularity to a single version of a URL for a single page of content. Consider the following 10 example URLs for the same fictional page of content:
- Canonical URL: http://www.example.com/directory 4/index.html
- Protocol duplication: https://www.example.com/directory 4/index.html
- IP duplication: http://62.184.141.58/directory 4/index.html
- Subdomain duplication: http://example.com/directory 4/index.html
- File path duplication: http://www.example.com/site/directory 4/index.html
- File duplication: http://www.example.com/directory 4/
- Case duplication: http://www.example.com/Directory 4/Index.html
- Special character duplication: http://www.example.com/directory%204/index.html
- Tracking duplication: http://www.example.com/directory 4/index.html?tracking=true
- Legacy URL duplication: http://www.example.com/site/directory.aspx?directory=4&stuff=more
The URLs may be fictional but I’ve worked with sites that had every one of these sources of duplicate content and more. In the worst cases, link popularity was split between more than 1,000 URLs for a single product page. That page would be much stronger if every link pointed to a single URL.
The most effective way to canonicalize duplicate content, consolidate link popularity and de-index the duplicates is with 301 redirects.
Cannibal
When two or more pages target the same keyword target, that’s cannibalization. Ecommerce sites fall into this trap frequently when usability necessities such as pagination, filtering and sorting, email to a friend and other functions create unique pages with some or all of the same content. Technically these pages are not exact duplicates. They need to exist for usability reasons so they can’t be canonicalized to a single URL with 301 redirects.
Site owners have two options in this case: Either differentiate the content to target different keyword themes, or apply a canonical tag to recommend consolidation of link popularity without redirecting the user.
Resolving Duplicate Content
Remember that 301 redirects are a SEO’s best friend when it comes to canonicalizing and resolving duplicate content. If a redirect is off limits because the URL needs to function for humans, a canonical tag is the next best bet for consolidating link popularity. There are other options for suppressing content — such as meta noindex, robots.txt disallow, and 404 errors — but these will only de-index the duplication without consolidating the link popularity. For more detailed information on resolving duplicate content, view this tutorial or this video from Google Webmaster Tools on duplicate content.



