Ecommerce business owners and managers have many good reasons to crawl their own websites, including monitoring pages, tracking site performance, ensuring the site is accessible to customers with disabilities, and looking for optimization opportunities.
For each of these, there are discrete tools, web crawlers, and services you could purchase to help monitor your site. While these solutions can be effective, with a relatively small about of development work you can create your own site crawler and site monitoring system.
The first step toward building your own, custom site-crawling and monitoring application is to simply get a list of all of the pages on your site. In this article, I’ll review how to use the Python programming language and a tidy web crawling framework called Scrapy to easily generate a list of those pages.
The Scrapy framework makes it relatively easy to create web spiders.
You’ll Need a Server, Python, and Scrapy
This is a development project. While it is relatively easy to complete, you will still need a server with Python and Scrapy installed. You will also want command line access to that server via a terminal application or an SSH client.
In a July 2015 article, “Monitor Competitor Prices with Python and Scrapy,” I described in some detail how to install Python and Scrapy on a Linux server or OS X machine. You can also get information about installing Python from the documentation section of Python.org. Scrapy also has good installation documentation.
Given all of these available resources, I’ll start with the assumption that you have your server ready to go with both Python and Scrapy installed.
Create a Scrapy Project
Using an SSH client like Putty for Windows or the terminal application on a Mac or Linux computer, navigate to the directory where you want to keep your Scrapy projects. Using a built-in Scrapy command, startproject, we can quickly generate the basic files we need.
For this article, I am going to be crawling a website called Business Idea Daily, so I am naming the project “bid.”
scrapy startproject bid
Scrapy will generate several files and directories.
Generate a New Scrapy Web Spider
For your convenience, Scrapy has another command line tool that will generate a new web spider automatically.
scrapy genspider -t crawl getbid businessideadaily.com
Let’s look at this command piece by piece.
The first term, scrapy, references the Scrapy framework. Next, we have the genspider command that tells Scrapy we want a new web spider or, if you prefer, a new web crawler.
The -t tells Scrapy that we want to choose a specific template. The genspider command can generate any one of four generic web spider templates: basic, crawl, csvfeed, and xmlfeed. Directly after the -t, we specify the template we want, and, in this example, we will be creating what Scrapy calls a CrawlSpider.
The term, getbid, is simply the name of the spider; this could have been any reasonable name.
The final portion of the command tells Scrapy what website we want to crawl. The framework will use this to populate a couple of the new spider’s parameters.
Define Items
In Scrapy, Items are mini models or ways of organizing the things our spider collects when it crawls a specific website. While we could easily complete our aim — getting a list of all of the pages on a specific website — without using Items, not using Items might limit us if we wanted to expand our crawler later.
To define an Item, simply open the items.py file Scrapy created when we generated the project. In it, there will be a class called BidItem. The class name is based on the name we gave our project.
class BidItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
Replace pass with a definition for a new field called url.
url = scrapy.Field()
Save the file and you’re done.
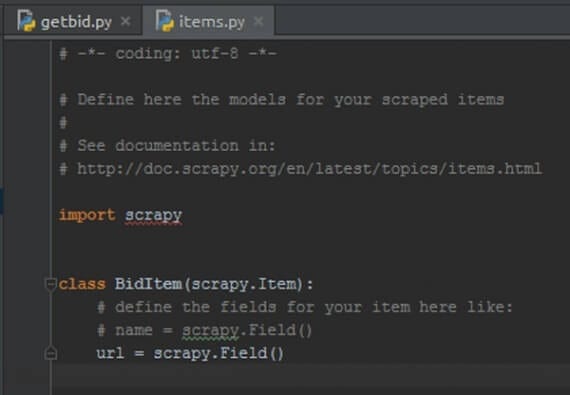
The item as it looked in an editor.
Build the Web Spider
Next open the spider’s directory in your project and look for the new spider Scrapy generated. In the example, this spider is called getbid, so the file is getbid.py.
When you open this file in an editor, you should see something like the following.
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule
from bid.items import BidItem
class GetbidSpider(CrawlSpider): name = 'getbid' allowed_domains = ['businessideadaily.com'] start_urls = ['http://www.businessideadaily.com/']
rules = ( Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True), )
def parse_item(self, response):
i = BidItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
We need to make a few minor changes to the code Scrapy generated for us. First, we need to modify the arguments for the LinkExtractor under rules. We are simply going to delete everything in the parenthesis.
Rule(LinkExtractor(), callback='parse_item', follow=True),
With this update, our spider will find every link on the start page (home page), pass the individual link to the parse_item method, and follow links to the next page of the site to ensure we are getting every linked page.
Next, we need to update the parse_item method. We will remove all of the commented lines. These lines were just examples that Scrapy included for us.
def parse_item(self, response): i = BidItem() return i
I like to use variable names that have meaning. So I am going to change the i to href, which is the name of the attribute in an HTML link that holds, if you will, the target link’s address.
def parse_item(self, response): href = BidItem() return href
Now for the magic. We will capture the page URL as an Item.
def parse_item(self, response): href = BidItem() href['url'] = response.url return href
That is it. The new spider is ready to crawl.
Crawl the Site; Get the Data
From the command line, we want to navigate into our project directory. Once in that directory, we are going to run a simple command to send out our new spider and get back a list of pages.
scrapy crawl getbid -o 012916.csv
This command has a few parts. First, we reference the Scrapy framework. We tell Scrapy that we want to crawl. We specify that we want to use the getbid spider.
The -o tells Scrapy to output the result. The 012916.csv portion of the command tells Scrapy to put the result in a comma separated value (.csv) file with that name.
In the example, Scrapy will return three page addresses. One of the reasons I selected this site for our example is that it only has a few pages. If you aim a similar spider at a site with thousands of pages, it will take some time to run, but it will return a similar response.
url https://businessideadaily.com/auth/login https://businessideadaily.com/ https://businessideadaily.com/password/email
With just a few lines of code, you’ve laid the foundation for your own site monitoring application.
See, also, “Monitor Accessibility Errors on Your Ecommerce Site with Scrapy, WAVE.”