Your site won’t rank if search engine bots can’t crawl it. And hidden doors that don’t impact human visitors can lock bots out.
Analyzing crawls will reveal and unlock the hidden doors. Then bots can enter your site, access your information, and index it so that it can appear in search results.
Use the following eight steps to ensure search bots can access your entire ecommerce site.
Site Blockers
Can bots enter the site?
First, check to see if you need to unlock the front door. The arcane robots.txt text file has the power to tell bots not to crawl anything on your site. Robots.txt is always named the same and located in the same place on your domain: https://www.example.com/robots.txt.
Make sure robots.txt doesn’t “disallow,” or block, search engine bots from your site.
Call your developer team immediately if your robots.txt file includes the commands below.
User-agent: *
Disallow: /Rendering
Can bots render your site?
Once they get through the door, bots need to find content. But they cannot immediately render some code — such as advanced JavaScript frameworks (Angular, React, others). As a result, Google won’t be able to render the pages to index the content and crawl their links until weeks or months after crawling them. And other search engines may not be able to index the pages at all.
Use the URL inspection tool in Google Search Console and Google’s separate mobile-friendly test to confirm whether Google can render a page, or not.

Use Search Console’s URL inspection tool to see how Google renders a page. This example is Practical Ecommerce’s home page. Click image to enlarge.
Sites using Angular, React, or similar JavaScript frameworks should pre-render their content for user-agents that can’t otherwise display it. “User-agent” is a technical term for anything that requests a web page, such as a browser, bot, or screen reader.
Cloaking
Are you serving the same content to all user agents, including search engine bots?
Cloaking is an old spam tactic to unfairly influence the search results by showing one version of a page to humans and a different, keyword-filled page to search engine bots. All major search engines can detect cloaking and will penalize it with decreased or no rankings.
Sometimes cloaking occurs unintentionally — what appears to be cloaking is just two content systems on your site being out of sync.
Google’s URL inspection tool and mobile-friendly test will also help with this. It’s a good start if both render a page the same as a standard browser.
But you can’t see the entire page or navigate it in those tools. A user-agent spoofer such as Google’s User-Agent Switcher for Chrome can check for sure. It enables your browser to mimic any user agent — i.e., Googlebot smartphone. User-agent spoofers in any leading browser will work, in my experience.
However, it typically requires manually adding Googlebot, Bingbot, and any other search engine user-agent. Go to the options or settings menu for your spoofer (a browser extension, typically) and add these four.
- Googlebot smartphone:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Googlebot desktop:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Bingbot mobile:
Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Bingbot desktop:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
Now you can turn your ability to spoof search engine bots on and off from your browser. Load at least your home page and ensure that it looks the same when you’re spoofing Googlebot and Bingbot as it does when you visit the site normally in your browser.
Crawl Rate
Do Google and Bing crawl the site consistently over time?
Google Search Console and Bing Webmaster Tools each provide the tools to diagnose your crawl rate. Look for a consistent trend line of crawling. If you see any spikes or valleys in the data, especially if it sets a new plateau for your crawl rate, check into what may have happened on that day.
Internal Link Crawlability
Are links on your site coded with anchor tags using hrefs and anchor text?
Google has stated that it recognizes only links coded with anchor tags and hrefs and that the links should have anchor text, too. Two examples are the “Will be crawled” links, below.
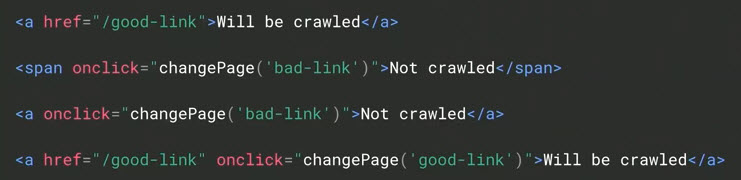
This hypothetical markup highlights the difference to Google between crawlable links and uncrawlable — “Will be crawled” vs. “Not crawled.” Source: Google.
Chrome includes helpful, preinstalled developer tools for link crawlability. Right-click any link and select “inspect” to see the code that makes that link visible.

In Chrome, right-click any link and select “Inspect” to see the code. Click image to enlarge.
Bot Exclusion
Are bots allowed to access the content they need to and excluded from seeing content that has no value to organic search?
The first step above was checking the robots.txt file to make sure that bots can enter your site’s front door. This step is about excluding them from low-value content. Examples include your shopping cart, internal search pages, printer-friendly pages, refer-a-friend, and wish lists.
Search engine crawlers will only spend a limited amount of time on your site. This is called crawl equity. Make sure that your crawl equity is spent on the most important content.
Load the robots.txt file on your domain (again, something like https://www.example.com/robots.txt) and analyze it to make sure that bots can and cannot access the right pages on your site.
The definitive resource at Robotstxt.org contains information on the exact syntax. Test potential changes with Search Console’s robots.txt testing tool.
URL Structure
Are your URLs properly structured for crawling?
Despite the hype about optimizing URLs, effective crawling requires only that URL characters meet four conditions: lowercase, alpha-numeric, hyphen separated, and no hashtags.
Keyword-focused URLs don’t impact crawling, but they send small signals to search engines of a page’s relevance. Thus keywords in URLs are helpful, as well. I’ve addressed optimizing URLs, at “SEO: Creating the Perfect URL, or Not.”
Using a crawler is one way to analyze the URLs on your site in bulk. For sites under 500 pages, a free trial of Screaming Frog’s will do the trick. For larger sites, you’ll need to purchase the full version. Alternatives to Screaming Frog include DeepCrawl, Link Sleuth, SEMrush, and Ahrefs, to name a few.
You could also download a report from your web analytics package that shows all of the URLs visited in the last year. For example, in Google Analytics use the Behavior > Site Content > All Pages report. Export it all (a maximum of 5,000 URLs at a time).
Once completed, sort the report of URLs alphabetically. Look for patterns of uppercase URLs, special characters, and hashtags.
XML Sitemap
Lastly, does your XML sitemap reflect only valid URLs?
The XML sitemap’s sole purpose is facilitating crawls — to help search engines discover and access individual URLs. XML sitemaps are a good way to be certain that search engines know about all of your category, product, and content pages. But sitemaps don’t guarantee indexation.
You first have to find your XML sitemap to see which URLs are in it. A typical URL is https://www.example.com/sitemap.xml or https://www.example.com/sitemapindex.xml. It can be named anything, though.
The robots.txt file should link to the XML sitemap or its index to help search engine crawlers find it. Head back to your robots.txt file and look for something like this:
Sitemap: https://www.example.com/sitemap.xmlIf it’s not there, add it.
Also, add the sitemap URL to Google Search Console and Bing Webmaster Tools.
Your XML sitemap should contain at least the same number of URLs as SKUs and categories, content, and location pages. If not, it could be missing key URLs, such as product pages.
Also, make sure the URLs in the XML sitemap are current. I’ve seen sitemaps with URLs from past versions of sites, discontinued products, and closed locations. Those need to be removed. Anything missing from your XML sitemap is at risk of not being discovered and crawled by search engines.
See the next installment: “6-step SEO Indexation Audit for Ecommerce.”