
JavaScript can improve a shopper’s buying experience, encourage interaction, and even bolster site performance in some cases. But where search engine optimization is concerned, JavaScript requires an extra degree of care.
Googlebot is busy. The web spider is responsible for crawling more than 130 trillion pages. If each web page took just one second to load, Googlebot would have more than four years’ worth of page loading and processing to fetch each page once.
The web spider is responsible for crawling more than 130 trillion pages.
Fortunately, Googlebot can crawl lots of pages at the same time. It can even render JavaScript. But, as Google’s Martin Splitt put it, “JavaScript requires an extra stage in the [crawling and indexing] process, the rendering stage.”
“Googlebot executes JavaScript when rendering the page, but because this rendering stage is expensive [in terms of time to execute] it can’t always be done immediately,” Splitt said. “Separating indexing and rendering allows us to index content that is available without JavaScript as fast as possible, and to come back and add content that does require JavaScript at a later time.”
The facts that JavaScript must be processed separately and a little latter are among several reasons ecommerce marketers will want to pay special attention as to how and why JavaScript is employed. For example, while we know that Googlebot can eventually “see” content added with JavaScript, it may be the case that the content will take longer to be indexed and, therefore, take longer to appear on Google search results.
This may not be a problem for a product detail page. It is likely the page will change little over time and will be in place for a long time. Thus an extra few days may be worth the wait. But an online store might want a new sale page or a holiday buying guide to appear in Google’s index and relevant SERPs as soon as possible.
Crawl, Render, Index
In July 2019, Google published a new, brief guide about JavaScript SEO. The guide describes the stages or steps Google takes to crawl, render, and index content that JavaScript adds to a page.
As we look at this process, it is important to understand that Googlebot will read and, presumably, index any conventional HTML content it finds. Thus the extra steps only apply to content that JavaScript adds to the page in the browser.

This diagram shows the steps Googlebot takes to parse and render page content. The process is iterative. Each time Googlebot finds a new URL, it adds it to the crawl queue. Source: Google.
Crawler. First, Googlebot gets the address for a page — say the category page on an ecommerce store — from the crawl queue, and follows the URL. Assuming the page is not blocked via robots.txt, Googlebot will parse the page. On the diagram above, this is the “crawler” stage.
At the crawler stage, any new links (URLs) that Googlebot discovers are sent back to the crawl queue. The HTML content on the parsed page may then be indexed.
Processing (rendering). At this point, the URL will be processed for JavaScript.
“How long it takes for Google to render your pages depends on many different factors, and we can’t make any guarantees here,” said Splitt.
Essentially, the page is placed in a render queue where it must wait its turn if you will.
Ultimately, Google will render content. Back in 2015, Merkle ran an experiment to determine how well Google renders JavaScript. Even then, Googlebot was doing a good job, and we can only assume that Google has improved at rendering and understanding JavaScript.
Once it renders the JavaScript, Googlebot will add new URLs it discovers to the crawl queue and move new content (content added via JavaScript) forward as executed HTML, to index.
Indexing. This stage adds the content, be it from the HTML or additional content from JavaScript, to Google’s index. When someone enters a relevant query on Google, the page may appear.
JavaScript SEO
Now that you (i) understand how Googlebot can render and read most modern JavaScript and (ii) recognize that JavaScript-driven content could take longer to show up in Google’s index, you can make better decisions about when and how to use JavaScript on an ecommerce site.
Here is a quick example. JavaScript can be used to lazy load images on a product category page. When the shopper visits this category page, all of the images that would appear on the visible screen are loaded. Other images, the ones that are “below the fold,” are not loaded until the shopper scrolls or swipes.
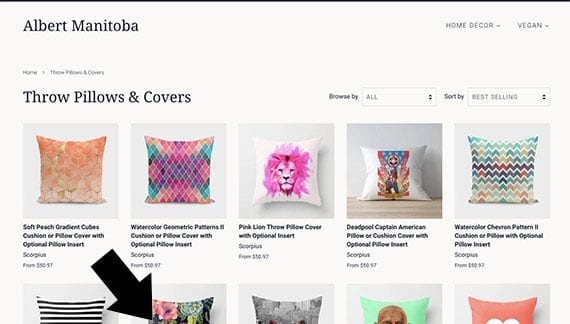
If JavaScript lazy loading were used in this product category page, only the images (or products) that appear on the visible screen (including partial images) would be loaded. Additional images and product information would load when the shopper scrolled or swiped.
This can help the page to load much more quickly and provide a better shopping experience. However, how this form of lazy loading is implemented can impact SEO. Does the JavaScript load just the image? Or does it make a call back to the database for all of the necessary product information?
In the former, Googlebot would see many or most of the links when it initially parses the HTML, while in the latter scenario it would not discover them until after processing.
My goal with this post is to explain how Google reads and renders JavaScript. With that basic understanding, you’re ready for more research on JavaScript and SEO, which are important for most ecommerce sites.
JavaScript SEO Resources
- “Understanding the JavaScript SEO Basics,” by Google
- “We Tested How Googlebot Crawls JavaScript And Here’s What We Learned,” by Adam Audette
- “JavaScript: SEO Mythbusting,” a video from Google
- “Make sure Google can see lazy-loaded content,” by Google
- “Technical SEO 101 for JavaScript Developers,” a presentation by Martin Splitt
- “Deliver search-friendly JavaScript-powered websites,” a presentation by Google’s Tom Greenaway and John Mueller


