
Every year at the “State of the Union” address, representatives from Google Search announce new features, drop tips, and give hints to the things that matter to the company. This year’s address at last week’s “Google I/O 19” conference is worth watching. The speakers are Google’s John Mueller and Martin Splitt.
What follows are my 13 takeaways from the address.
- Google search will soon expand into 3D and AR. Augmented reality will launch in web search later in May with three-dimensional models appearing in Google’s Knowledge Graph. For instance, you’ll be able to see selected animals in search results as 3D models and then view in your environment. You’ll be able to partner with Google to do the same with product models, similarly to how Ikea offers the ability to see furniture in your home via its app. New Balance, Samsung, Target, and Wayfair are already working on this new search feature, reportedly.
- Google’s goal is 100-percent mobile-first. We knew that more than 50 percent of the sites in Google’s index are mobile-first, but now Google has also confirmed that over 50 percent of sites ranking in Google’s search results pages are mobile sites as well. If you don’t have an optimal mobile experience, now is the time to start. Mobile is rapidly becoming a necessity for organic search success. Mobile-first indexing is Google’s future, and having a responsive site is the easiest way to get there.
- Google is focusing on images in search results. Roughly a fourth of the address was dedicated to image-related topics. It’s important to Google. Images are more than just visually attractive. They convey context instantly in what otherwise might take several sentences or paragraphs of text. Google is using this contextual strength in its search results to allow searchers to “intentionally navigate to the content,” whether they’re looking to buy a product from an ecommerce site or wanting a how-to guide or information.
How do you get your images to rank? Optimizing the text and metadata around your images helps Google understand the image’s contextual relevance. It’s worth noting that Mueller said nothing about Google’s visual recognition abilities. Do not rely on Google to automatically detect what’s in your images.
- Google does not crawl images in CSS files. Speaking of image optimization, if you want your images to rank in search results, embed them into your page using the HTML tag that contains an alt attribute, such as <img src=”image.jpg” alt=”image description”>. Calling the images within a CSS <div> tag will not get them indexed.
- Google Discover wants your high-resolution images. You can sign up today to include your large images in Google’s Discover feed. This may be a precursor to ranking large-format images in other Google search properties. Since many ecommerce sites have these product images anyway, making them available in Google Discover could send someone looking to see the precise detail in a product to your site to purchase.
- Googlebot now runs on modern Chromium. Previously Googlebot used an outdated version of Chrome, which meant that Googlebot couldn’t process many of the things that your Chrome browser could. Googlebot reportedly acquired over 1,000 new capabilities with this update.
Google has pledged to make this change “evergreen,” saying that Googlebot will always run the modern version of Chromium. This is big news in search engine optimization, and will likely lead to some interesting changes in technical best practices as we learn more about Googlebot’s new crawling abilities.
- Googlebot’s user agent will be changing. The change is coming at an undisclosed time, which Google promises to announce widely in advance. There have been some rare reports of user agents based on Android 9.0.0 and newer Chrome versions, which has even Splitt, who made the announcement, confused. If you’re using user agent detection, use pattern matching rather than an exact match to future-proof your code.
- Three new forms of structured data. Using the Schema.org protocol, Google wanted to make sure that search optimizers and developers know about structured data markup for that can result in rich snippets for how-to content, question-and-answer pages that cover one topic, and pages that contain multiple questions and answers.
- Use Google’s Indexing API to request crawls for job postings and livestream videos. You can submit URLs directly to Google for indexing for time-sensitive content — currently job postings and livestream videos — through Google’s Indexing API. The content must be marked up with the appropriate structured data to qualify.
- Google wants hrefs in HTML links. This is not the first time Google made this statement. But it’s worth repeating, as ecommerce sites frequently create links in JavaScript or other languages that don’t contain an href are thus not crawlable links to Googlebot.
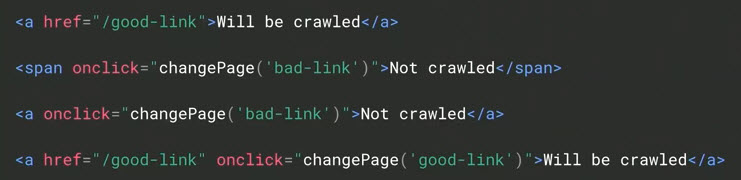
This hypothetical markup highlights the difference to Google between crawlable links and uncrawlable — “Will be crawled” vs. “Not crawled.”
Using visual processing, Google may detect non-HTML links after the original crawl, but it usually takes much longer. Save yourself the stress and make HTML links an SEO requirement.
- Google respects robots.txt disallows. There continue to be one-off examples of the index containing disallowed pages, but the Google representatives reiterated that it respects those robots.txt disallows. Keep in mind that if you disallow a page after it has been indexed, it can take months to remove. If you want something to be de-indexed quickly, 301 redirect it to a relevant page, put a meta robot <noindex> tag on it, and request indexing in Search Console’s URL Inspection tool.
- Google’s index contains 130 trillion pages. The next time you’re unhappy about your crawl rate, ruminate on that number and then use the URL inspection tool to request indexing faster.
- Google Search Console to report page speed. Sign up for the trial program to get page speed reports directly in Google Search Console. Site speed may be a developer’s responsibility, but it’s one of Google’s ranking factors. Ecommerce merchants should understand the impact of speed.



