
Monitoring competitors’ prices and product lineups can help online retailers win pricing battles; optimize sales and special offers; and track product trends over time. For many small ecommerce businesses, however, keeping tabs on the competition is a painful, manual process.
Fortunately, thanks to an easy-to-use application framework called Scrapy almost anyone can create a web spider to crawl competitors’ websites and collect pricing data. If you can read HTML and CSS, you can make Scrapy work.
Before diving into a demonstration of how you can use Scrapy, it is worth mentioning that there are certainly plenty of good services that will help online sellers track competitors or even develop winning, dynamic pricing strategies — examples include Wiser, Price Trakker, and Upstream Commerce, to name a few.
If you can afford one of these services, your business may not need to build your own price monitoring bot. But for relatively small retailers that find these services expensive, Scrapy is a good, easy-to-employ option.
The Scrapy Application Framework Is Easy
Although using Scrapy requires you to write code, building web scraping bots is actually a lot easier than many other common web development tasks. A beginner with a willingness to try should be able to use Scrapy successfully.
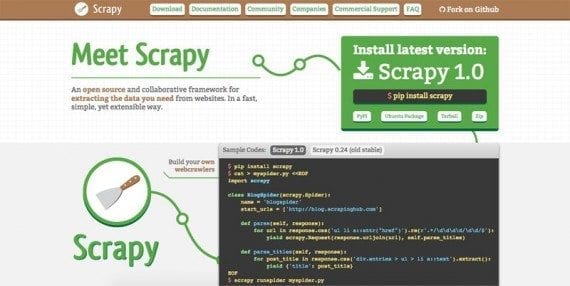
Scrapy is an application framework for creating web spiders.
In fact, the most difficult part will be identifying the elements on the page that you want to scrape. For this you will need to be familiar with HTML structures and CSS selectors.
Finally, Scrapy is relatively easy for at least three more reasons: (a) It uses Python, a very common and easy to write programming language; (b) it will run on Mac OS X, Linux, and Windows, so you won’t need to bring up a server, and (c) it is a framework, so there is relatively little code to write.
Seeking Comic Prices
To demonstrate how to use Scrapy, consider the hypothetical case of Al, a comic book retailer. The comic book trade is very competitive, and while new comics have cover prices that generally represent the going rate for the first couple of months after publication, the price of a back issue or collectable comic can change fast.
Al wants to ensure that his back issues and collectable comics, which he sells in his own brick-and-click store and on eBay, have current, market-right prices. Al also buys lots of comics, so it is important for him to track prices over time, so he can discover trends.
One of the sites that Al wants to monitor is Things From Another World (TFAW), a popular comic retailer. On TFAW, Scrapy will collect prices for Dark Horse Comics’ Mass Effect series.
The Scrapy spider we will build will first locate the product links on TFAW’s Mass Effect page (a product category page) and follow those links to each Mass Effect comic’s product detail page, where it will collect the pricing information.
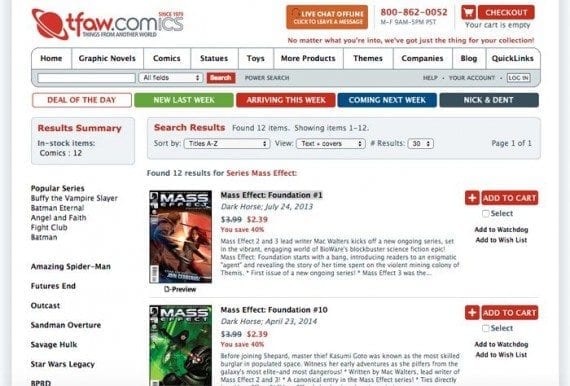
The spider will start crawling on one of TFAW’s product category pages.
Install Python and Scrapy
To use the Python-powered Scrapy application framework, you need to ensure that you have the following services, packages, and software loaded on your computer or server.
- At least Python 2.7,
- The pip package manager,
- Python setuptools,
- The lxml Python Library,
- The OpenSSL Library.
If you’re using a computer running OS X or Linux, the process could hardly be easier.
For example, on a Mac, Python is already be installed. So you simply need to download the pip package manager, open a terminal, and type a few commands.
You’ll find a copy of the pip package manager at https://bootstrap.pypa.io/get-pip.py.
Once downloaded, open your Mac’s terminal, navigate to the directory you downloaded the get-pip.py file to, and run the following command.
sudo python get-pip.py
You should be asked to enter your password. This is the same password you use to log into your Mac. This should get you both the pip package manager and the Python setup tools.
Next, run the command below to update a package called six. This is to a avoid a known issue with six and Scrapy.
sudo pip install --upgrade six
Finally, install Scrapy.
sudo pip install Scrapy
Windows requires a couple of extra steps, which are outlined on the Scrapy website at http://doc.scrapy.org/en/1.0/intro/install.html.
Create a Scrapy Project
In your computer’s terminal navigate to the directory where you want to keep your Scrapy web crawlers, and create a new Scrapy project with the frameworks startproject command.
scrapy startproject tfaw
This command has three parts. The word scrapy tells your computer that you want to use the Scrapy framework. As one might expect, startproject indicates that you want to create a new Scrapy project. Finally, in the example, tfaw is the name of the project. You may, of course, name your Scrapy project almost anything you want.
The framework will automatically generate a few directories and files, so that you should have a project structure that looks something like this one.
tfaw/
scrapy.cfg
tfaw/
__init__.py
__init__.pyc
items.py
pipelines.py
settings.py
settings.pyc
spiders/
Create Item Definitions
In the example project files shown above, notice the file items.py. This file is used to describe the things you want to collect from a target web page. When you first open items.py, it should look like the following.
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TfawItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
As you look at this code, notice first that Scrapy named your new item class after the project name (“tfaw” was our project name), capitalizing the first letter to follow a convention for naming classes.
class TfawItem(scrapy.Item):
Next, notice that Scrapy gives you instructions about how to define items for your web spider. Remember these items are essentially a list of the information you want to collect from the product detail page.
# define the fields for your item here like: # name = scrapy.Field()
To decide what to put here, our hypothetical comic book seller, Al, visits one of the product detail pages on the TFAW website. He decides that he wants the product’s title, UPC, and, of course, price. These items can be added in the items.py file — like the following.
class TfawItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
upc = scrapy.Field()

An important step is to decide what you want to scrape from the page.
For our project, we also want to grab the product detail page’s URL. This way, if there is ever an error with our pricing bot, we can go to the source.
The completed items.py file looks like this.
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TfawItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
upc = scrapy.Field()
url = scrapy.Field()
As an aside, space has meaning in Python. So try to stay lined up with the same indents and spacing shown. Also, you will want to use a code editor or basic text editor to modify your items.py file. Never use a word processor like Microsoft Word.
Create Your Scrapy Spider
Return to your computer’s terminal and create a new Scrapy spider.
scrapy genspider massEffect tfaw.com
This command has four parts.
First, scrapy tells your computer to use the Scrapy framework. As one might expect, genspider tells your computer that you want to generate a new spider.
The next option is the unique name that you want to give your spider. In our example, we will be getting the prices for the Mass Effect comic book series, so the spider is named, massEffect. You can give your spider almost any meaningful name you want. Finally, we specify which domain the spider will crawl. In our example, this is tfaw.com.
This command will create the code for a new Scrapy spider and place it in your project’s spider’s directory. The filename for your new spider will be the same as the name you gave it in your genspider command, so for our project the spider’s filename is massEffect.py.
When you open this file in your code editor, it should look just like this.
# -*- coding: utf-8 -*-
import scrapy
class MasseffectSpider(scrapy.Spider):
name = "massEffect"
allowed_domains = ["tfaw.com"]
start_urls = (
'http://www.tfaw.com/',
)
def parse(self, response):
pass
Target Your Start URL
The first step toward customizing your Scrapy spider is to identify the URL where the spider will start crawling. By default, Scrapy made the start URL the same as the allowed domain.
start_urls = (
'http://www.tfaw.com/',
)
Since in our example, Al, the hypothetical comic store owner, wants to scrawl the Mass Effect category page, we’ll set the start URL to http://www.tfaw.com/Companies/Dark-Horse/Series?series_name=Mass+Effect.
start_urls = (
'http://www.tfaw.com/Companies/Dark-Horse/Series?series_name=Mass+Effect',
)
Next, change the parentheses to brackets.
start_urls = [
'http://www.tfaw.com/Companies/Dark-Horse/Series?series_name=Mass+Effect',
]
Parse the Product Category Page
Later when we command the spider to crawl, it will look at the parse function for instructions. In our example, we are going to start by collecting the URLs for the individual Mass Effect comics, so we need to add some instructions in the parse function.
As a reminder, you should be starting with an empty parse function.
def parse(self, response):
pass
If we take a look at the Mass Effect category page on the TFAW site, we notice that the product titles are links to specific product detail pages. So we want our spider to follow these, but we need to give this Scrapy spider a way to identify them.

On the TFAW category page, the comic book titles are links to specific product detail pages.
Scrapy allows us to do this in a couple of ways. We can use CSS selectors, so the same selectors we use to add style to a web page, or we can use XPath, a query language for selecting nodes in a document (selecting the HTML tags). Don’t worry, both of these are easier than you might think.
To help explain, take a look at the updated parse function I created using a CSS selector.
def parse(self, response):
for href in response.css('div a.boldlink::attr(href)'):
url = response.urljoin(href.extract())
yield scrapy.Request(url, callback=self.parse_detail_page)
The first line that I added creates an iterator. The important words are for and in.
for href in response.css('div a.boldlink::attr(href)'):
This line says that “for each individual thing in a group of things, do what comes on the following lines.”
As a shorthand, the individual thing is represented by a variable called href in the example, and the group of things is called response. We could have named the individual things just about anything, like link, selection, or even Fred, but descriptive names are better.
The group of things, response.css(), is a list, if you will, of elements that the spider found on the product category page. In this case, CSS is being used as the means of identification.
Effectively, we are telling the spider to locate all of the a tags with a class of boldlink which are inside of a div element and get their href attribute.
If you have seen CSS before this should be familiar. In fact, the only difference between this CSS selector and what you would see in a simple CSS file is ::attr() — which Scrapy uses to indicate that we want an attribute of the selected element.
div a.boldlink::attr(href)
Let’s take some time and go over how Scrapy finds the links.
With this command Scrapy will go to the TFAW website and find all of the div elements.
For each of the div elements, it will look for a child anchor or a element, so that it will have a collection of div elements that contain an a elements.
Continuing further, the spider will check to see if the a elements it has collected have a class (. is an indicator of class in CSS) of boldlink.
If the a element has the boldlink class, the spider will look for and capture its href attribute. If not, it will ignore the element.
A look at the code from the TFAW site may help. I used ellipses for the URL to make the code fit a bit better. Notice the parent child relationship between the div and the a elements.
<div style="margin-bottom: 3px; margin-top: 0px;">
<a class="boldlink" href="..." name="427354">Mass Effect: Foundation #1</a>
</div>
To identify this relationship, I used Chrome’s developer tools. In Chrome, right click (alternate click) on the TFAW title. A menu should appear. Select “Inspect Element” and you should see the underlying code.
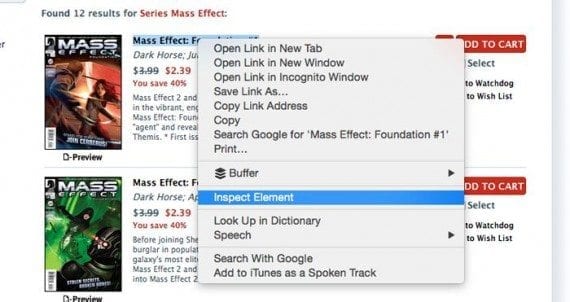
Web browsers frequently include development tools that will help you identify the elements on the page. In Google Chrome, right click on the element you want to inspect.
Let’s stop for a moment and run a little test to see if we are, in fact, getting the elements that we want.
Take the parse function code from above, and comment out the next two lines, adding a # in from of each.
def parse(self, response):
for href in response.css('div a.boldlink::attr(href)'):
#url = response.urljoin(href.extract())
#yield scrapy.Request(url, callback=self.parse_detail_page)
After these lines add the following.
print href
Now, go back to your computer’s terminal and navigate to your Scrapy project. Once you are in the project directory, enter the following command.
scrapy crawl massEffect
As you might expect, this will send the massEffect spider to crawl its target. Your terminal will display information about the crawl, including something like the following for each of the links it encountered.
<Selector
xpath=u"descendant-or-self::div/...@href"
data=u'/Companies/Dark-Horse-Series/Profile/Mas'>
Notice that in the data section, we have part of the URL path. We know that we are getting the proper elements. As long as we did not get any other elements, our spider is working so far.
Return to the parse function code.
def parse(self, response):
for href in response.css('div a.boldlink::attr(href)'):
url = response.urljoin(href.extract())
yield scrapy.Request(url, callback=self.parse_detail_page)
The next line is indented, indicating that it is one of the things the spider should do for each of the individuals in the group.
url = response.urljoin(href.extract())
This command has two parts. First, there is a variable, url, which will be used to store some information. Like all variables, this can be just about any name that you want, but something meaningful is usually better.
Second, there is a response object, which represents the groups of links that scrapy got back when it crawled the TFAW site using the CSS selector. This response object has a special method called urljoin.
response.urljoin()
The urljoin method has a special job. It concatenates (chains together) the allowed domain and the value of the parameter we pass to it. We need this because the TFAW site uses relative URLs.
When our spider crawled the site and got the links, the URL that came back looked like the following.
/Companies/Dark-Horse-Series/Profile/MassEffect...
Notice that it does not start with an http or the TFAW domain name.
In web development, relative URLs are generally a good idea. Web browsers are smart enough to know that the full URL should really start with the protocol and the domain name. But our spider does not make those sorts of assumptions. It does only what it is told. So we need to let it know to add the tfaw.com domain in front of the link information it retrieved. The urljoin method does just that when we pass it an individual link stored in the variable href.
url = response.urljoin(href.extract())
For this line, the last thing to notice is that we added another method, extract(), to our href object to tell Scrapy that we want just the value of the data not the entire object to be concatenated.
The next line in parse takes the URL for the individual product detail page and tells Scrapy to go crawl that page. When it is done, Scrapy should look for another function, which we have not yet created, named parse_detail_page and do what that function tells it to do.
yield scrapy.Request(url, callback=self.parse_detail_page)
This command can be divided into a few parts.
First, we have the Python yield keyword. This is a special Python feature that returns what’s called a generator. For our purposes, you simply need to know that yield gets the result of what follows, which in this case is a Scrapy crawl.
The next part is a Scrapy request.
scrapy.Request()
Scrapy uses Request and Response objects when it crawls a web page. The Request object sends the spider out to get data, which is returned as a Response object.
We are passing the Scrapy request two parameters. First the URL of the product detail page that we collected earlier and, second, the name of a new function that we want Scrapy to run once it has a response. As a matter of convention, functions called after a response or action are referred to as callbacks or a callback.
yield scrapy.Request(url, callback=self.parse_detail_page)
Parse the Product Detail Page
The Scrapy spider we’ve been building is already pretty amazing. It will:
- Visit a product category page on the TFAW site;
- Find all of the individual links to product detail pages;
- Modify the URL to each product detail page so that page can be crawled, too;
- Pass each individual URL to a new function.
The next step then is to write the parse_detail_page function and start collection the pricing data. Here is the finished function.
def parse_detail_page(self, response):
comic = TfawItem()
comic['title'] = response.css('div.iconistan + b span.blackheader::text').extract()
comic['price'] = response.css('span.blackheader ~ span.redheader::text').re('[$]\d+\.\d+')
comic['upc'] = response.xpath(‘...’).extract()
comic['url'] = response.url
yield comic
The first line in this section of code defines the function. It uses the def keyword to declare that we will be creating a new function. It defines the name of the function, parse_detail_page, and it passes to parameters, including our response from the last Request. The colon at the end is required.
def parse_detail_page(self, response):
The first line inside of the function associates the variable comic with the item class that we created earlier.
comic = TfawItem()
The next four lines are a series of declarations or associations, if you will.
In each case, we added information to comic. You should notice that the first two declarations are using CSS to identify the parts of the TFAW product detail page that Al, our comic storeowner, wanted to capture.
comic['title'] = response.css('div.iconistan + b span.blackheader::text').extract()
comic['price'] = response.css('span.blackheader ~ span.redheader::text').re('[$]\d+\.\d+')
Let’s take a moment and examine the CSS selectors used. In the first of these two, notice that I have added ::text to the end. This is an important distinction for Scrapy. If I had not used ::text the Scrapy spider would have grabbed the element, which in this case is a span with the class, blackheader. When I add ::text, I am in effect telling the spider that I want the text inside of the span rather than the span itself.
comic['title'] = response.css('div.iconistan + b span.blackheader::text').extract()
Using extract() at the end retrieves the data rather than the object, as described above.
The next line is a bit different in that it does not end with extract() rather we have re(), with a rather odd-looking parameter [$]\d+\.\d+.
comic['price'] = response.css('span.blackheader ~ span.redheader::text').re('[$]\d+\.\d+')
In this case, we are getting the price from the TFAW product detail pages, but the text for the price includes a phrase, “Your Price:,” followed by the actually price. For our price monitoring, Al is not going to need that phrase, so I used what is called a regular expression to remove the words and return just the price.
The re() method first does what the extract() method does (gets the text from the element), but then it filters the result based on the regular expression.
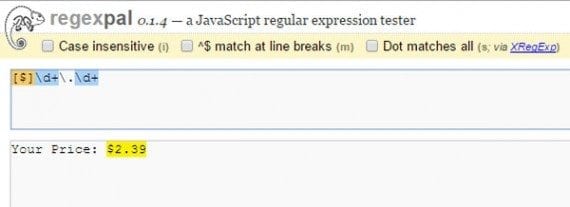
Regular expressions can define selections within text.
I used an online tool called RegexPal to help define the regular expression. Without going into too much detail about how regular expressions work, know that you can use them to select a part of a string of text.
[$]\d+\.\d+
So in this case the [$] looks for a $ in the text. The \d+ selects one or more digits. The \. allows for the decimal in the price, and again \d+ selects one or more digits.
In your spiders, you can use regular expressions this way too.
The next line of the function introduces us to an XPath selector. In the example, I am using an ellipse as a placeholder, but don’t worry, I will show you what is in there.
comic['upc'] = response.xpath(‘...’).extract()
XPath is expressed as a list of elements with slashes in between. So the XPath table/tr/td would select the all of the td elements that had a tr element as a parent and a table element as a grandparent.
You can usually identify an XPath by looking at the code, and recognizing the relationship between elements.
Here is an example. Again, the XPath for the td would be table/tr/td.
<table>
<tr>
<td valign="top">Availability: </td>
<td valign="top">Released</td>
</tr>
</table>
A browser web development tool will often show you an XPath. Just be careful. Some web development tools will include elements that should be there but are not.
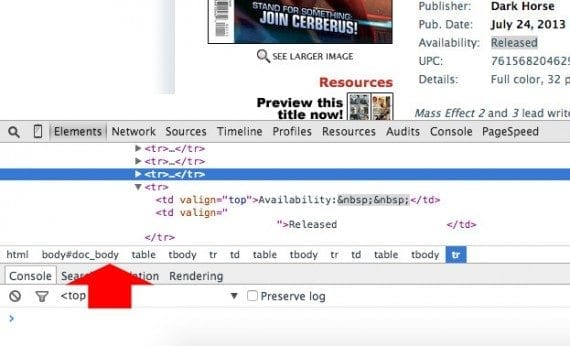
A web browser’s development tools will often show the XPath or a list of elements from which the XPath can be identified..
For example, Chrome shows tbody elements in the XPath even though they are not actually there. The TFAW website uses a very ugly table structure, so ultimately the XPath ended up looking like this.
/html/body/table[1]/tr/td[4]/ table[3]/tr/td/table/tr/td[contains(., "UPC:")] /following-sibling::td[1]/text()
For further information about XPath, Scrapy has some good examples on its site. ZVON.org also has a great explanation of how to use XPath.
The last of the four declarations is the simplest.
comic['url'] = response.url
It simply captures the URL that we passed from the parse function to this parse_detail_page function.
The last line in the spider yields the results of the spider’s efforts.
yield comic
Start Monitoring Prices
The spider is complete. While it certainly took me a lot of words and examples to describe it, I hope it did not seem too complicated.
The only thing that remains is to crawl the TFAW site and get the price data that Al wanted. To do this, go back to your computer’s terminal, navigate to the Scrapy project directory and run the following command to get the price data as a comma separated value (CSV) that you can read with Google Sheets, Microsoft Excel, or really any spreadsheet software.
scrapy crawl massEffect -o results.csv
The first part of this command should look familiar since we used it before. It tells Scrapy to send the spider out to crawl its target pages.
scrapy crawl massEffect
The next bit outputs (-o) the results of the crawl to a file named results.csv. I could have called this file just about anything I wanted and so long as I added the .csv extension, I would get the spreadsheet I am looking for.
If you open results.csv in a text editor, it should look something like the example below.
url,price,upc,title http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-4___433370,$2.39,76156820462900411,Mass Effect: Foundation #4 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-12___450605,$2.39,76156820462901211,Mass Effect: Foundation #12 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-2___429269,$2.39,76156820462900211,Mass Effect: Foundation #2 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-7___440094,$2.39,76156820462900711,Mass Effect: Foundation #7 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-3___431314,$2.39,76156820462900311,Mass Effect: Foundation #3 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-13___452713,$2.39,76156820462901311,Mass Effect: Foundation #13 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-8___442437,$2.39,76156820462900811,Mass Effect: Foundation #8 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-1___427354,$2.39,76156820462900111,Mass Effect: Foundation #1 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-11___448663,$2.39,76156820462901111,Mass Effect: Foundation #11 http://www.tfaw.com/Companies/Dark-Horse-Series/Profile/Mass-Effect%3A-Foundation-10___446357,$2.39,76156820462901011,Mass Effect: Foundation #10
If we open this same file in Google Sheets, it is easy to see that we have successfully crawled the site and captured prices.
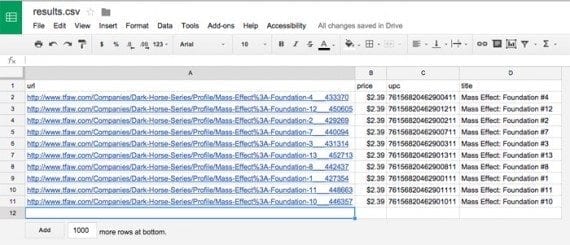
The resulting CSV file can be opened as a spreadsheet.
Summing Up
Even the smallest of ecommerce businesses can write a web spider using Scrapy and collect pricing information.
Our hypothetical storeowner, Al, will need to run his bot weekly, and actually use the data he collects. If TFAW changes its page layout, Al will need to update the spider, but this should be a lot easier than manually visiting the page every week.
Building a series of these spiders is a lot faster and more efficient than manually checking prices.



