
Sometimes websites have search-engine-optimization problems that Google Search Console, Google Analytics, and off-the shelf SEO tools cannot locate. When this occurs, I often rely on an old-school method: web server logs.
What Are Web Server Logs?
You may assume that Google Analytics or similar analytics platforms record every visit to your site. However, analytics platforms do not record most robot visits, including search engine bots.
Web server logs, however, record every visit to your site, whether from humans or robots. Think of web server logs as automated journals of all the activity on your site. They typically include the originating IP address of the visitor, the browser-user agents, the pages requested, and the page where the visitor came from.
The main challenge with server logs is that information is in a raw format. You need to take extra steps to analyze the data.
For example, here’s what an Apache combined log format looks like.
66.249.64.34 - frank [05/Apr/2017:13:55:36 -0700] "GET /product-123 HTTP/1.1" 200 2326 "http://www.webstore.com/home.html" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
I’ve underlined the key parts of the log: the IP address of the visitor, the time of the visit, the page visited, the referring page, and the visitor or bot. You can use the IP address to verify Googlebot visits.
3 Examples of Using Server Logs
Here are three recent examples where I used web server logs to get to the root of SEO problems.
The first example comes from my work with a multinational corporation. Google Search Console > Crawl > Sitemaps reported more than 100,000 pages in the XML sitemaps, but Google indexed less than 20,000 of them. However, Search Console > Google Index > Index Status reported more than 70,000 pages indexed.
How is this possible?
Google can index many duplicate or stale pages and miss the “real” pages of a site. The hard part is determining which duplicate pages are indexed and which real pages aren’t.
Unfortunately, Google Search Console doesn’t provide a list of indexed URLs or tell you which pages from your XML sitemaps are not indexed. To address the problem, we needed the answer to both of those questions.
In this case, I received server logs covering the end of January to the beginning of March. After analyzing them, we learned that less than 9 percent of the pages in the XML sitemap had been crawled by Google during that period.
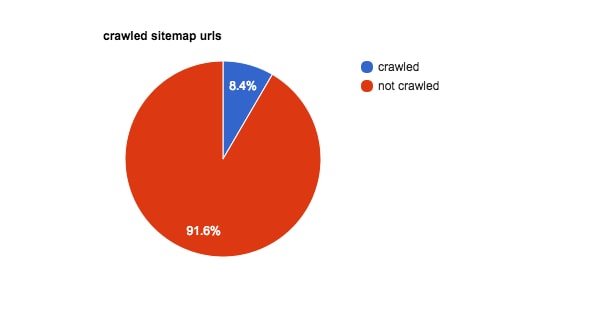
In this client’s case, 91.6 percent of sitemap URLs were not crawled.
When we looked closely at the pages not crawled, we found that most of them had exactly the same content and template. The only difference was the name of the product. It appeared Googlebot had not crawled them due to the pages having identical content. In addition to this, we confirmed that Googlebot was wasting time on bot traps.
I’ve address bot traps, or infinite crawl spaces, previously. They often appear in websites with extensive databases — such as most ecommerce platforms — and causes search-engine robots to continue fetching pages in an endless loop. An example of this is faceted or guided navigation, which can produce a near limitless number of options. Infinite crawl spaces waste Googlebot’s crawl budget, and could prevent indexing of important pages.
The solution in this case was a painful process of writing unique content for each page, starting with the best selling products. (Measuring the investment in unique content can help determine if it makes sense to do this.)
The second example comes from a large site in the auto industry. We migrated the site to HTTPS and faced many re-indexation delays that hurt the site’s organic search rankings.
This case was particularly challenging because we suspected that the site had serious bot traps, but we had to process terabytes of log data from multiple web servers, classify pages by page type, and emulate the functionality of Search Console > Crawl > URL Parameters to understand the problem.
The breakdown by page type allowed us to narrow down the bot trap issue to the “Year-Make-Model-Category” URL group. Next, we wanted to see if an unusual number of pages crawled — due to the URL parameters — could lead us to the bot trap.
Our log analysis helped us identify the problem. We found three new URL parameters that didn’t appear in the Search Console > Crawl > URL Parameters list, but they were getting more visits than expected. (Categorizing URL parameters helps Google avoid crawling duplicate URLs.) The fact they were not listed in Search Console > Crawl > URL Parameters prevented us from fixing the problem. I assumed Google would list any parameters we needed to be worried about, but this was wrong. We had close to 100 problem URL parameters.
The topic of URL parameters can be confusing. URL parameters are set dynamically in a page’s URL, and can be driven by its template and its data sources. URL parameters are made of a key and a value separated by an equals sign (=) and joined by an ampersand (&). The first parameter always comes after a question mark in a URL.
Virtually every ecommerce platform has dynamic pages that are automatically generated from database content. These dynamic pages often use URL parameters to help the ecommerce application present the right content. One example of this is paginated category pages, as follows.
- http://www.webstore.com/shoes
- http://www.webstore.com/shoes?page=2
- http://www.webstore.com/shoes?page=3
- http://www.webstore.com/shoes?page=4
In this case, “page” is a URL parameter. Google considers it an active parameter because it changes or affects the page content. In Google Search Console, we would set up the parameter in Crawl > URL Parameters. This will instruct Google to crawl each page so it can pick up canonical tags, and pagination tags.
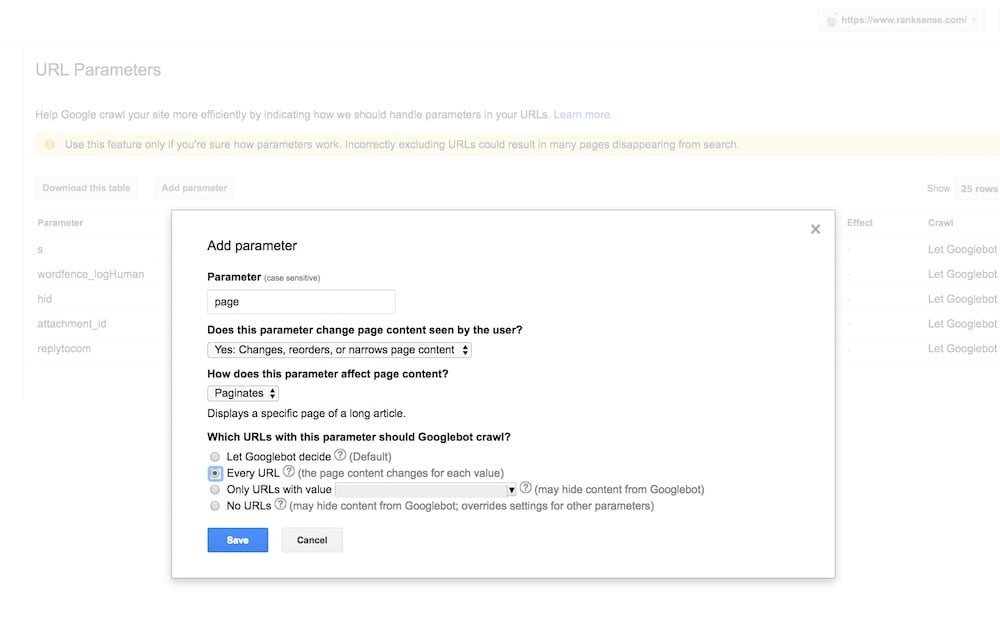
Setting up the “page” parameter in Search Console > Crawl > URL Parameters. Click image to enlarge.
Another example is a parameter we add to the pages for tracking purposes, to know, say, which marketing campaigns are performing better.
- http://www.webstore.com/shoes?utm_source=Google
- http://www.webstore.com/shoes?utm_source=Bing
- http://www.webstore.com/shoes?utm_source=Facebook
In this case, the parameter is “utm_source,” which is a standard Google Analytics tracking parameter. It doesn’t affect page content. Google considers this a passive parameter.
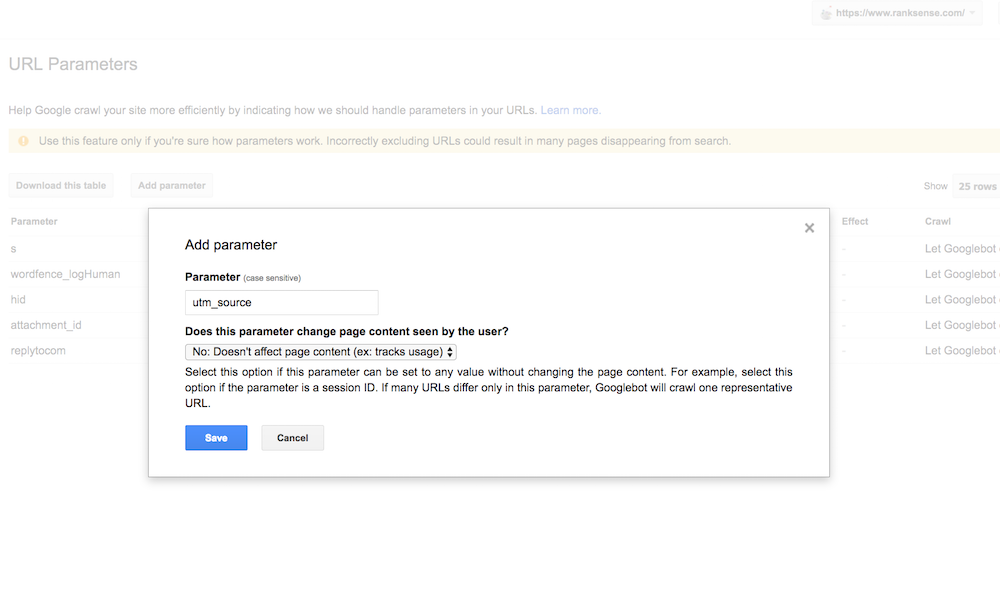
Setting up “utm_source,” in Search Console > Crawl > UTM Parameters. Google considers this a passive parameter. Click image to enlarge.
The last example involves a popular web publisher. Our challenge here was that we knew there were duplicate pages on the site, but when we ran ScreamingFrog, a spider tool, we couldn’t find them because they were not linked internally. However, when we searched in Google, we could see a few in the search results — confirming that they were indexed. Guessing URLs to check is not particularly scalable. Web logs to the rescue!
We downloaded log data from the end of February to close to the end of March and focused on getting the answer to the question: Which URLs has Googlebot crawled that are not included in the XML sitemap?
When you do this type of analysis, if the site is a blog, you can expect to see listings of articles in a category and pages with redundant URL parameters because those pages are generally not included in XML sitemaps. I generally recommend including listing pages — such as listings of articles in a category — in separate XML sitemaps (even if you assign canonical tags to them), because it helps to confirm if they are getting indexed.
Using server logs, we were surprised to find a number of useless pages with the same page titles as other legitimate pages on the site, but no unique content. We didn’t know these pages existed, but Googlebot was able to find them and, unfortunately, index many of them. Thus the site requires some serious cleanup work to remove the useless pages.
As an aside, Googlebot can find web pages that spider tools, such as ScreamingFrog, cannot — for the following reasons.
- Google uses links from any site on the web, not just internal links.
- WordPress sites, and most blog platforms, ping search engines when new content is created.
- Google has a long memory. If the page was crawled in the past, Google could re-crawl it in the future
- Google doesn’t confirm this, but it could discover new pages from Chrome or Google Analytics logs.
Transforming Raw Log Data
We write code for all clients’ log analyses. Here is a simplified two-step process to get started.
First, convert the log data to a structured data format, such as CSV, using a regular expression — a “regex.” Here is a regular expression that works in PHP.
^(\S+) \S+ \S+ \[([^\]]+)\] "[A-Z]+\s([^\s]+) [^"]+" \d+ \d+ "[^"]*" "([^"]*)"$
Regular expressions can be a complicated, especially if you are not a web developer. In a nutshell, regular expressions are search patterns. You may be familiar with wildcards. An example is using the term *.docx in your computer command line to list all Microsoft Word documents in a directory. Regular expressions allow for similar, but more sophisticated, searches.
Use Regular Expressions 101 to validate and understand how the regex above works. Enter the regular expression above into the tool. You’ll also need to enter a test string. For this example, I’ll use the Apache log example that was underlined, earlier in the article.
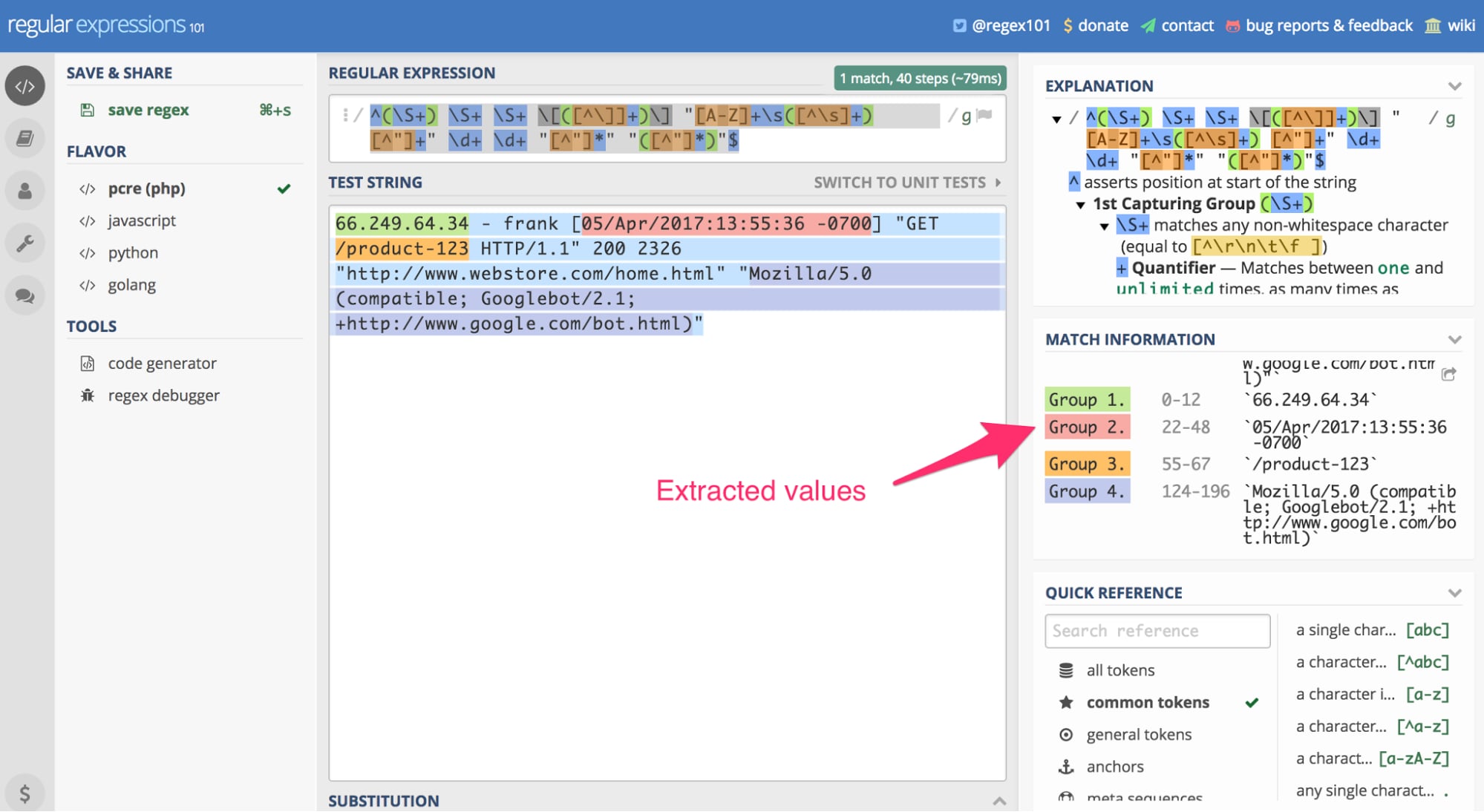
Using RegEx 101, we can paste the server log entry referenced earlier in the article as a “test string” and apply the above regular expression. The result is our extracted data. Click image to enlarge.
In this case, the tool uses the regex search pattern on the above-reference server log entry to extract the Googlebot IP, the date of the visit, the page visited, and the browser user agent (in this case, Googlebot).
If you scroll down in the “Match Information” section on the right, you’ll see the extracted information. This regular expression works specifically with the Apache combined log format. If your web server is Microsoft IIS or Nginx, as examples, this regex won’t work.
The next step is to write a simple PHP script to read the log files, one line at a time, and execute this regex to search and capture the data points you need. Then you’ll write them to a CSV file. You can find an example-free script that does this here. The code is six years old, but, as I’ve said, web server logs are old school.
After you have the log entries in CSV format, use a business intelligence tool — which retrieves and analyses data — to read the file and get answers to your questions. I use Tableau, which is expensive. But there are many other options that start with a free tier, such as Microsoft Power BI.
Recommended

Remembering Hamlet Batista
February 8, 2021

