
Evaluating the performance of cloud-based vendors can be tricky. You can read reviews, but it’s sometimes difficult to find unbiased opinions.
One little-known method of evaluating cloud platforms is to analyze their status pages. They provide a high-level overview of the platform’s operational status. Many status pages also include a history of incidents, including recent problems.
Status pages are typically managed by the engineering or development teams. The pages are usually factual, without a marketing angle.
Locating a Status Page
Status pages are often hosted on a different domain. This ensures that the page will stay online even if the primary site does not. (Although Amazon’s AWS status page failed last year when its principal servers went down.) Sometimes they use a subdomain, such as status.[providername].com, or a separate domain, such as [providername]status.com.
If the status pages aren’t linked from the primary site, you’ll have to do some searching, such as “shopify status page” or “magento status page.”
Still, some cloud services might not have a public status page. For smaller ones that could be acceptable. But for larger companies, the lack of a status page is a major warning sign, in my experience.
Interpreting a Status Page
Once you find a status page, how do you use it to evaluate the service? I’ll use Shopify’s page, which is among the most helpful, to illustrate.
Shopify segregates its service into seven systems. That is good. It shows that the company thought about how its service could fail and is reporting on those functions.
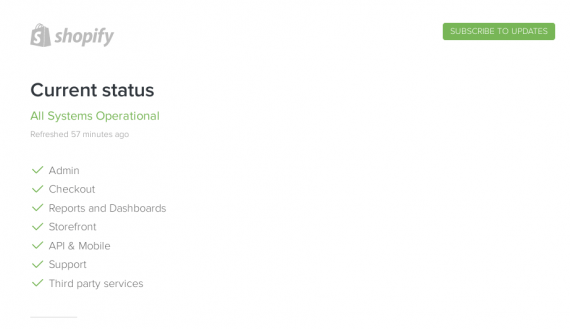
Shopify’s status page is separated into seven key functions.
—
Shopify also includes average response times. While the absolute numbers aren’t meaningful, it is useful to view the history to observe potential disruptions. Reporting response times is also transparent, which boosts users’ confidence.
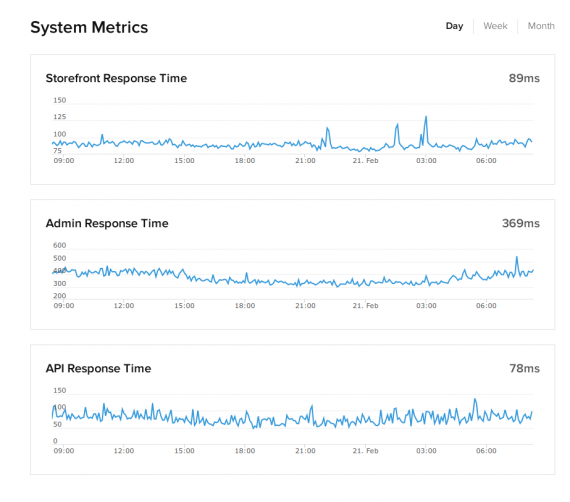
Reporting response times can disclose potential disruptions. It is also admirably transparent.
—
At the bottom of Shopify’s status page is a timeline of past incidents. It includes details of the incident, what went wrong, and when it was fixed.
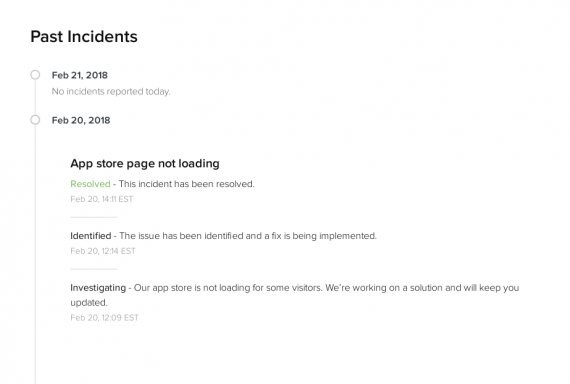
Shopify’s status page includes past incidents, with details of what went wrong and when it was fixed.
Evaluating Status
To evaluate a cloud-based service, start by reading through the incidents in the past year. Try to identify patterns. Look for recurring problems.
Does one component have the most glitches? Is it critical or merely nice-to-have?
Consider how quickly issues are detected and fixed. A helpful incident report should include the time it was discovered, the time a fix was developed, the time the fix was implemented, and a plan for preventing its reoccurrence.
Be skeptical with how quickly a service reports a problem and a fix. In my experience, many classes of incidents are under-reported or even ignored by a service until enough customers complain about it.
If a status page reports no incidents in, say, the past month, there’s a good chance the company is under-reporting problems or faking its transparency. Both are bad. There is no service that is 100-percent incident free.
A status page provides (some) evidence to evaluate the service. Does the company promote a feature that seems to have status problems? Does it claim high performance and speed but the status page shows otherwise?
What you learn from a status pages makes for excellent questions for the sales team, before you sign up.
Critique of Status Pages
Shopify’s status page, as noted above, does many things correctly. However, it could include better resolution notes. Instead of stating, “This incident has been resolved,” the page could explain how it was resolved and how Shopify will prevent it from happening again.
Magento’s status page is too rosy. I’m dubious. According to Magento’s incident history, the last problem was five weeks ago. For a system as large and complex as Magento’s, that’s unrealistic.
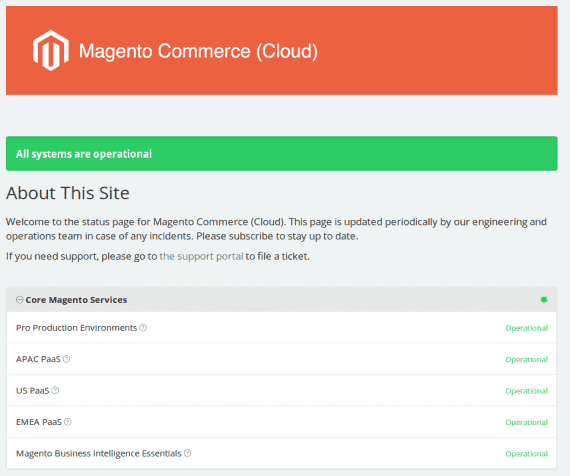
Magento’s incident history claims the last problem was five weeks ago.
—
Amazon’s AWS status page is among the most complex. It discloses a lot. This is helpful, but it is also difficult to understand. Even finding the list of past AWS incidents is not easy.
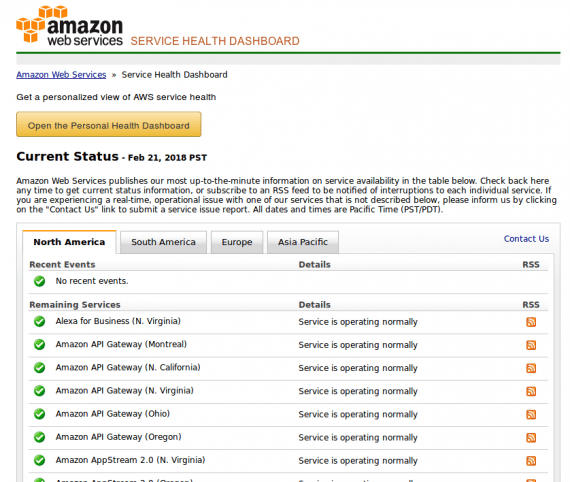
Amazon’s AWS status page is among the most complex. It is helpful but it’s also difficult to interpret.



